
Bot Traffic là lượng request do bot tạo ra (crawler, scraper, scanner) thay vì người dùng thật. Dùng khi website bị chậm, log “ngập bot”, số liệu GA4/GSC lệch, hoặc cần điều phối crawl budget để Google/AI quét đúng trang quan trọng.
Lợi ích chính: giảm tải hệ thống, giảm rác index, giữ đường crawl cho trang chuyển đổi, và tăng khả năng nội dung được AI trích dẫn đúng bối cảnh.
1. Bot Traffic trong SEO: khi nào tốt, khi nào phá? #
Bot Traffic có lợi khi là bot tìm kiếm/giám sát hợp lệ. Có hại khi là bot quét, scrape, brute-force hoặc giả mạo UA gây tải và làm bẩn dữ liệu. Không phải mục tiêu “chặn hết bot”, mà là phân loại đúng để chặn bot xấu và “nuôi” bot tốt đi đúng đường đến trang tạo giá trị.
| Nhóm bot | Ví dụ phổ biến | Tác động | Hành động khuyến nghị |
|---|---|---|---|
| Bot tìm kiếm | Googlebot, Bingbot | Crawl/index, cập nhật nội dung mới | Cho vào, tối ưu đường đi (sitemap, internal link, canonical, tốc độ) |
| Bot “tool” hợp lệ | Uptime monitor, công cụ SEO | Tốn tài nguyên nhưng hữu ích | Rate-limit/allow theo IP nếu cần |
| Bot xấu | Scraper, scanner, brute-force | Chậm web, tăng 403/404/5xx, rủi ro bảo mật | Chặn WAF/CDN + server, theo hành vi (rate/path/ASN) |
Bot Traffic là tổng request do chương trình tự động tạo ra, trong bối cảnh vận hành website và Technical SEO.
Ví dụ: GA4 user không tăng nhưng server CPU tăng đột biến vì hàng nghìn request vào /wp-login.php hoặc các URL tham số lọc.
UA (User-Agent) là chuỗi thông tin mà trình duyệt hoặc bot gửi kèm trong mỗi HTTP request để “tự giới thiệu” mình là ai (loại phần mềm, hệ điều hành, đôi khi cả phiên bản). Trong bối cảnh Bot Traffic, UA hay được dùng để phân loại nhanh bot/trình duyệt, nhưng không đủ tin vì bot xấu có thể giả UA.
Ví dụ UA của trình duyệt (Chrome trên macOS):
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36Ví dụ UA của bot:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)UA dùng khi nào trong thực chiến? #
- Dùng để lọc nhanh log: top UA nào đang hit nhiều, UA nào tạo 403/404/429 nhiều.
- Dùng để chặn “scanner phổ biến” (nikto, sqlmap, masscan…) ở lớp server/WAF.
- Không dùng UA làm bằng chứng duy nhất để allowlist Googlebot.
Đúng khi / Sai khi #
- Đúng khi: UA + hành vi (rate, path, status code) + IP/DNS verify (với bot quan trọng) cùng khớp.
- Sai khi: thấy UA “Googlebot” rồi tin luôn và mở cửa toàn bộ.
Nếu bạn paste 1–2 dòng log mẫu (IP + URL + status + UA), mình sẽ chỉ ra ngay: UA đó “nghiêm túc” hay “đội mũ giả”.
2. Bot tốt vs bot xấu: checklist phân loại để quyết “chặn/cho/giới hạn” #
Phân loại theo mục tiêu (crawl/index, giám sát, audit, tấn công) và theo hành vi (rate, path, status code) cho quyết định chính xác hơn UA. UA chỉ là “nhãn” và bị giả rất dễ. Hành vi + log mới là bằng chứng vận hành.
| Tiêu chí | Đúng (bot nên cho/giới hạn) | Sai (bot nên chặn) | Cách đo |
|---|---|---|---|
| Mục tiêu | Crawl nội dung + sitemap hợp lý | Quét lỗ hổng, brute-force, scrape | Top URL bị hit + referrer + pattern endpoint |
| Hành vi | Rate ổn định, ít spike | Burst cao, quét dải URL | Request/phút theo IP/UA |
| Đường truy cập | Bài viết, category, sitemap | /wp-login, /xmlrpc, file nhạy cảm | Top path 24h |
| Tín hiệu lỗi | 200/304 là chủ đạo | Nhiều 404/403/429 | Tỷ lệ status code |
Output: 1 bảng danh sách “Allow / Rate-limit / Block” theo UA/IP + 1 bảng “Top URL bị bot đập”.
- ☐ Top 20 User-Agent (24h)
- ☐ Top 20 URL bị hit (24h)
- ☐ Top 20 IP tạo 403/404/429 (24h)
- ☐ Gắn nhãn: Allow / Rate-limit / Block
- ☐ Ghi chú “ngoại lệ” (API hợp lệ, webhook, admin IP thay đổi)
2.1. Dấu hiệu nhận biết bot (bot thật, bot giả, bot phá) #
Nhận biết bot chính xác nhất dựa vào hành vi (tần suất, đường dẫn, status code, pattern quét) hơn là chỉ dựa vào User-Agent. User-Agent có thể bị giả rất dễ. Bot thật thường có hành vi “có mục đích”, còn bot phá thường có hành vi “quét rộng, burst mạnh, đánh endpoint nhạy cảm”.
| Tín hiệu | Bot tốt (thường gặp) | Bot giả / bot phá (thường gặp) | Hành động khuyến nghị |
|---|---|---|---|
| Tần suất (rate) | Ổn định, ít burst | Burst theo giây/phút, tăng đột ngột ban đêm | Rate-limit / Challenge / Block |
| Đường dẫn (path) | Hit sitemap, bài viết, category hợp lý | Đánh /wp-login.php, /xmlrpc.php, /.env, /.git, search nội bộ | Block theo path ở WAF/CDN |
| Status code | 200/304 chủ đạo | 403/404/429 dày đặc, đôi khi kéo theo 5xx | Chặn sớm để giảm tải |
| Pattern crawl | Crawl theo cụm (cluster), có logic | Quét dải URL, tham số lọc/sort vô hạn (crawl trap) | Dọn crawl trap + disallow pattern rác |
| User-Agent (UA) | Nhất quán, dễ đối chiếu | Rỗng, đổi liên tục hoặc giả “Googlebot” | Không tin UA 100%, kiểm bằng hành vi |
| Referrer | Có thể rỗng (bot thường rỗng) | Referrer giả/loạn để đánh lừa | Không dùng referrer làm tiêu chí chính |
| IP/ASN | Ổn định theo nhà cung cấp | IP thay đổi liên tục, dải IP “độc lạ” | Block theo ASN/IP khi có bằng chứng |
| Mục tiêu nội dung | Đọc trang phổ biến/quan trọng | Scrape bảng, FAQ, đoạn “answer-first” | Challenge + chống scrape + theo dõi hit |
2.2. Checklist nhận biết bot trong 3 phút (không cần tool phức tạp) #
Chỉ cần 4 câu hỏi: ai vào nhiều nhất, vào URL nào, tạo lỗi gì, và có burst không là đã phân loại được 80%. Mục tiêu là ra quyết định Allow/Rate-limit/Block nhanh, không phải ngồi “đọc log cho vui”.
Output: Danh sách 10 IP/UA đáng chú ý + nhãn hành động (Allow / Rate-limit / Block).
- ☐ Top 20 User-Agent trong 24h (UA nào chiếm nhiều nhất?)
- ☐ Top 20 URL bị hit (có tập trung vào login/xmlrpc/search/param không?)
- ☐ Top IP tạo 403/404/429 (có trùng với UA/URL đáng nghi không?)
- ☐ Có burst theo phút/giây không (đột biến ban đêm)?
2.3. Dấu hiệu “bot giả danh Googlebot” (đừng allowlist nhầm) #
Bot giả danh Googlebot thường lộ qua hành vi quét endpoint nhạy cảm, burst cao và tỷ lệ lỗi lớn. User-Agent ghi “Googlebot” không phải bằng chứng. Nếu một IP “Googlebot” mà lại hit /wp-login.php hoặc quét tham số loạn, đó gần như chắc chắn là bot giả.
Output: Danh sách IP tự xưng Googlebot cần verify DNS + danh sách IP fail verify để block.
- ☐ UA có chữ “Googlebot” nhưng hành vi quét login/xmlrpc/.env/.git
- ☐ Burst cao theo giây/phút
- ☐ 404/403/429 dày đặc
- ☐ Không hit sitemap hoặc không crawl theo cụm nội dung
- ☐ Fail verify DNS (reverse + forward)
2.4. Dấu hiệu “bot scrape content” (copy bảng, FAQ, đoạn ngon) #
Bot scrape thường tập trung vào trang có bảng/FAQ, request theo pattern đều đặn và có thể lấy nhiều trang liên tiếp trong thời gian ngắn. Nếu thấy một IP/UA “đọc” quá nhiều bài có cấu trúc (bảng, FAQ) theo nhịp máy chạy, đó là tín hiệu scrape.
Output: Danh sách IP/UA scrape + rule WAF challenge/rate-limit + theo dõi hit theo giờ.
- ☐ Hit nhiều bài có bảng/FAQ liên tiếp (đặc biệt ban đêm)
- ☐ Không có hành vi giống người (không assets, không delay tự nhiên)
- ☐ Tần suất đều, nhịp máy chạy
- ☐ Referrer rỗng hoặc giả
- ☐ Tạo spike băng thông (download KB tăng)
3. Đọc log để phân biệt bot thật và bot giả (không cần đoán mò) #
Log giúp thấy ai đang ăn tài nguyên và đánh vào URL nào. Bot giả thường lộ qua burst + path bất thường + tỷ lệ lỗi cao. Nếu không đọc log, chặn sai rất dễ: chặn nhầm bot tốt hoặc bỏ sót bot xấu “nhìn như người”.
Output: 3 bảng: Top UA, Top URL, Top IP theo lỗi (403/404/429) để ra quyết định chặn.
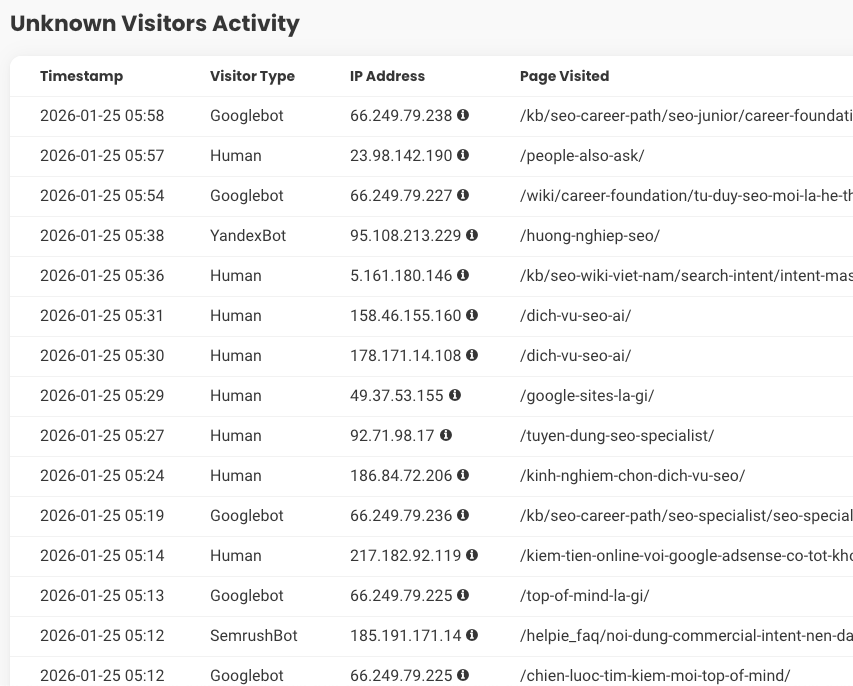
3.1. Lọc nhanh log (Nginx/Apache) để ra danh sách bot #
Chỉ cần lọc 3 thứ: UA, URL, IP lỗi là đủ thấy 80% vấn đề bot traffic. Mục tiêu là tạo “danh sách hành động” (block/rate-limit/allow), không phải ngắm log.
Output: 3 danh sách Top 30: User-Agent, URL, IP theo lỗi.
# 1) Top User-Agent (ổn định hơn nếu log có nhiều dấu ")
awk -F\" '{print $(NF-1)}' /var/log/nginx/access.log | sort | uniq -c | sort -nr | head -30
# 2) Top URL (lấy URL từ request line, rồi cắt querystring)
awk -F\" '{print $2}' /var/log/nginx/access.log \
| awk '{print $2}' \
| sed 's/\?.*$//' \
| sort | uniq -c | sort -nr | head -30
# 3) Top IP theo 403/404/429 (đỡ lệ thuộc vị trí cột)
awk -F\" '{
split($1,a," "); ip=a[1];
split($3,b," "); status=b[2];
if (status ~ /^(403|404|429)$/) print ip
}' /var/log/nginx/access.log | sort | uniq -c | sort -nr | head -30Nếu dùng Cloudflare và không có Nginx/Apache, vẫn làm được bằng cách xuất log/analytics từ Cloudflare rồi xử lý tương tự trong Sheets. Gợi ý đọc nền tảng: Log File Analysis.
3.2. Verify Googlebot thật trước khi chặn (tránh tự bắn chân) #
UA “Googlebot” có thể bị giả. Cần xác minh bằng reverse DNS và forward DNS với các IP tự xưng Googlebot hit nhiều. Chỉ cần verify nhóm “ảnh hưởng SEO” (Googlebot/AdsBot), không cần verify mọi bot lặt vặt.
Output: danh sách IP Googlebot đã verify + danh sách IP giả để block.
# IP -> hostname (reverse DNS)
host 66.249.66.1
# hostname -> IP (forward DNS) để đối chiếu
host crawl-66-249-66-1.googlebot.com- ☐ Lấy 5 IP “Googlebot” hit nhiều nhất trong 24h
- ☐ Reverse DNS từng IP
- ☐ Hostname phải thuộc domain Google hợp lệ
- ☐ Forward DNS và đối chiếu IP khớp IP ban đầu
- ☐ Fail → coi như bot giả, xử lý như bot xấu
4. Checklist chặn bot theo 4 lớp: WAF/CDN → Server → WordPress → robots.txt #
Chặn càng gần “cửa” càng tốt: ưu tiên WAF/CDN, rồi mới tới server và WordPress. Robots.txt chỉ là lớp hướng dẫn bot tuân chuẩn. Nếu bot xấu bị chặn sau khi đã vào PHP/MySQL thì bạn vẫn trả “chi phí tài nguyên” cho nó.
| Lớp | Chặn được | Ưu điểm | Rủi ro |
|---|---|---|---|
| WAF/CDN | Burst, scanner, bot xấu theo hành vi | Giảm tải trước server | Rule quá gắt có thể gây false positive |
| Nginx/Apache | Path/UA/rate | Chủ động, chi tiết | Deploy sai có thể 403 diện rộng |
| WordPress | Login/XML-RPC/API endpoint | Dễ làm với site nhỏ | Không chặn được bot trước khi PHP chạy |
| robots.txt | Bot ngoan (tuân chuẩn) | Chuẩn SEO, minh bạch | Không phải cơ chế “ẩn index” |
4.1. Cloudflare/WAF: bộ rule tối thiểu cho WordPress #
Chặn brute-force và scanner ở WAF thường cho hiệu quả nhanh nhất: giảm request vào endpoint nhạy cảm và giảm lỗi 5xx. Rule tốt là rule “ít chữ”: tập trung vào path nhạy cảm + rate + hành vi.
Output: 1 rule rate-limit login, 1 rule block xmlrpc (nếu không dùng), 1 rule chặn file nhạy cảm.
- ☐ Rate-limit:
/wp-login.php(5–10 req/phút/IP tùy site) - ☐ Block hoặc challenge:
/xmlrpc.php(nếu không dùng) - ☐ Chặn truy cập:
/.env,/.git,/wp-config.php,/phpmyadmin - ☐ Challenge UA rỗng + burst
- ☐ Không chặn theo quốc gia/ASN nếu chưa có bằng chứng từ log
| Rule | Dùng khi | Nguy cơ | Cách giảm rủi ro |
|---|---|---|---|
| Rate-limit wp-login | Login bị đập ban đêm | Admin bị chặn nhầm | Allow admin IP / tăng burst hợp lý |
| Block xmlrpc | Không dùng Jetpack/ứng dụng cần xmlrpc | Hỏng tích hợp | Kiểm tra plugin trước khi block |
| Challenge UA rỗng | Log có UA empty nhiều | Webhook hợp lệ | Allow endpoint webhook theo path |
4.2. Nginx: chặn endpoint nhạy cảm + rate-limit #
Nginx phù hợp khi bạn đã có “danh sách vấn đề” từ log và cần cắt nhanh bot xấu theo path/rate. Ưu tiên chặn theo path trước; chặn theo UA chỉ dùng cho scanner phổ biến vì UA dễ bị giả.
Output: 1 snippet chặn xmlrpc + 1 rule rate-limit wp-login.
# http { ... } (đặt trong nginx.conf hoặc file include ở cấp http)
limit_req_zone $binary_remote_addr zone=login_zone:10m rate=5r/m;
server {
# Block xmlrpc (nếu không dùng)
location = /xmlrpc.php { return 403; }
# Rate-limit wp-login
location = /wp-login.php {
limit_req zone=login_zone burst=10 nodelay;
try_files $uri =404;
}
}4.3. Apache/.htaccess: chặn cơ bản theo path và UA #
Apache chặn nhanh theo rewrite rule, phù hợp shared hosting hoặc site nhỏ chưa có WAF. Luôn test phạm vi nhỏ và có khả năng rollback để tránh 403 nhầm.
Output: 1 nhóm rule chặn xmlrpc + 1 nhóm rule chặn scanner phổ biến.
RewriteEngine On
RewriteRule ^xmlrpc\.php$ - [F,L]
RewriteCond %{HTTP_USER_AGENT} (masscan|nikto|sqlmap|python-requests|curl/) [NC]
RewriteRule .* - [F,L]4.4. WordPress: giảm bot rác vào PHP/MySQL #
Với WP, bot rác thường đánh vào login/xmlrpc và tạo URL rác bằng search/param; dọn đúng giúp giảm tải PHP rõ. Nếu có WAF/server thì chặn trước; WP layer là lớp “phòng thủ cuối”.
Output: tắt/giới hạn xmlrpc (nếu không dùng), hardening login, hạn chế URL rác từ search/param.
- ☐ Tắt XML-RPC nếu không dùng (hoặc giới hạn theo IP)
- ☐ Bật 2FA và giới hạn login attempts
- ☐ Kiểm soát search nội bộ tạo URL rác (nếu không cần index)
- ☐ Bật cache đúng để bot tốt crawl “nhẹ”
4.5. robots.txt: mẫu thực chiến “chặn đường cụt” nhưng không chặn bừa #
robots.txt nên chặn các đường dẫn nội bộ không cần Search và các pattern tạo crawl trap; đồng thời khai báo sitemap để bot tốt đi đúng map. Không nên dùng Disallow: /*?* cho mọi site vì có thể chặn nhầm trang hợp lệ có query; hãy chặn theo pattern rõ và kiểm bằng log.
Output: 1 robots.txt chạy được + danh sách pattern “cần chặn theo site”.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
# Chặn search nội bộ tạo URL rác (nếu không muốn index)
Disallow: /?s=
Disallow: /search/
# Một số pattern WP hay gây crawl waste (chỉ bật khi log cho thấy bị crawl nhiều)
Disallow: /*?replytocom=
Disallow: /*?orderby=
Disallow: /*?filter=
Sitemap: https://www.vlink.asia/sitemap_index.xmlTài liệu nội bộ liên quan: Robots.txt Optimization và Advanced Robots.txt Rules.
5. “Nuôi bot” đúng nghĩa: cho bot tốt ăn đúng phần (crawl ít mà trúng) #
5.1. robots.txt để “nuôi bot”: chặn đường cụt, mở đường cho trang quan trọng #
robots.txt “nuôi bot” tốt nhất khi nó giúp bot tìm kiếm đi thẳng vào sitemap và khu vực nội dung có giá trị, đồng thời tránh các URL rác gây crawl trap. Ưu tiên chặn theo pattern cụ thể (dựa trên log), không chặn theo kiểu “quét sạch” /*?* vì dễ chặn nhầm URL hợp lệ.
Output: 1 file robots.txt chạy được + 1 danh sách “pattern cần chặn” lấy từ log (replytocom, orderby, add-to-cart, sort/filter rác…).
| Nhóm URL | Nên làm gì trong robots.txt | Vì sao | Kiểm bằng |
|---|---|---|---|
| Trang cần index (KB, dịch vụ, pillar) | Không disallow; dẫn bot bằng sitemap + internal link | Giữ crawl tập trung vào trang tạo giá trị | Log hit Googlebot vào money page |
| WP admin | Disallow /wp-admin/ + Allow admin-ajax | Chuẩn vận hành WP | Không ảnh hưởng index |
| Search nội bộ | Disallow /?s= và /search/ (nếu không muốn index) | Giảm URL rác | Top URL bị hit trong log |
| Tham số rác (crawl trap) | Disallow theo pattern cụ thể (replytocom, orderby, filter…) | Tránh bot lạc vào mê cung tham số | Log + GSC Crawl Stats |
5.2. robots.txt mẫu “nuôi bot” cho WordPress (an toàn, không chặn bừa) #
Mẫu dưới đây giữ đường crawl sạch cho bot tìm kiếm: chặn khu vực admin và các “đường cụt” phổ biến, đồng thời khai báo sitemap để bot đi đúng map. Các dòng chặn tham số là dạng “bật khi cần”, chỉ dùng khi log cho thấy bị crawl nhiều hoặc tạo quá nhiều URL vô nghĩa.
Output: robots.txt (v1) + danh sách tham số cần chặn theo site.
User-agent: *
# 1) Giữ bot ra khỏi admin, nhưng vẫn cho admin-ajax chạy
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
# 2) Chặn search nội bộ nếu bạn không muốn index trang tìm kiếm
Disallow: /?s=
Disallow: /search/
# 3) Chặn các "đường cụt" WP hay tạo crawl waste (BẬT KHI CẦN, dựa trên log)
Disallow: /*?replytocom=
Disallow: /*?orderby=
Disallow: /*?filter=
Disallow: /*?sort=
Disallow: /*?page=
Disallow: /*?add-to-cart=
Disallow: /*?wc-ajax=
# 4) Khai báo sitemap để bot đi đúng map
Sitemap: https://www.vlink.asia/sitemap_index.xml5.3. Checklist “nuôi bot” bằng robots.txt (có tiêu chí đúng/sai) #
Checklist này giúp robots.txt phục vụ đúng mục tiêu: bot tốt crawl đúng trang, bot không lãng phí vào URL rác. Mỗi thay đổi robots.txt đều phải có log trước/sau để tránh chặn nhầm.
Output: file robots.txt v2 + bảng đối chiếu “trước/sau” (Top URL bị hit, Googlebot hit money page).
- ☐ robots.txt trả 200 và tải nhanh (không 403/5xx, không redirect vòng)
- ☐ Sitemap index khai đúng URL, truy cập được
- ☐ Không chặn nhầm khu vực nội dung cần index (KB, dịch vụ, pillar)
- ☐ Chỉ chặn tham số sau khi thấy nó tạo crawl waste trong log
- ☐ Không dùng
Disallow: /*?*nếu chưa chứng minh site không cần query hợp lệ - ☐ Sau khi chỉnh robots, kiểm tra Googlebot vẫn crawl sitemap và money page đều
- ☐ Nếu GSC/Crawl Stats tụt mạnh: rollback và kiểm tra pattern bị chặn nhầm
5.4. Ngoại lệ quan trọng khi “nuôi bot” bằng robots.txt #
Không có một robots.txt “chuẩn cho mọi site”. Robots tốt là robots khớp hành vi URL thật của site và mục tiêu index. Các site có filter faceted navigation, tracking query, hoặc ecommerce thường có query hợp lệ. Chặn bừa sẽ làm mất crawl các trang có giá trị.
| Trường hợp | Vì sao dễ chặn nhầm | Cách làm đúng | Tiêu chí đạt |
|---|---|---|---|
| Ecommerce (add-to-cart, sort, filter) | Query tạo UX, đôi khi có landing hợp lệ | Chặn theo tham số rác; canonical/noindex cho trang filter không cần | Bot giảm hit URL rác, trang sản phẩm vẫn crawl đều |
| Site có tracking UTM | Query hợp lệ cho đo lường | Không chặn UTM bằng robots; xử lý bằng canonical/param rules | Index sạch, tracking vẫn chạy |
| Search nội bộ dùng thật | Search tạo URL vô hạn | Disallow search nếu không muốn index; hoặc noindex trang search | Không nổ index URL search |
Gợi ý đọc nền tảng: Log File Analysis.
5.5. Phân loại bot theo mục đích (để quyết định Allow / Rate-limit / Block) #
Phân loại bot theo “mục đích + mức độ tin cậy + mức tiêu tốn tài nguyên” giúp xử lý đúng: bot tìm kiếm thì nuôi, bot SEO tool thì giới hạn, bot xấu thì chặn. Không có “danh sách bot đầy đủ cho mọi website”, vì bot thay đổi liên tục. Cách đúng là dùng taxonomy (nhóm) + map theo log để ra quyết định.
Bảng này gắn tên bot (User-Agent / token) với mục đích và hành động mặc định (Allow / Rate-limit / Block). Dùng để ra quyết định nhanh: chặn bot phá, hạn chế bot tool, và “nuôi” bot tốt để tăng cơ hội được AI trích dẫn. Nhìn vào 1 hàng là biết: bot đó vào để làm gì, nên xử lý ở lớp nào, và cách xác thực để tránh chặn nhầm.
| Nhóm bot | Tên bot hay gặp (UA / robots.txt token) | Vào để làm gì | Hành động mặc định | Cách xác thực nhanh (tránh chặn nhầm) |
|---|---|---|---|---|
| Search Indexing (bot xếp hạng) |
Google: Googlebot, Googlebot-Image, Googlebot-Video, Googlebot-News Bing: bingbot | Crawl để lập chỉ mục, hiểu nội dung, phục vụ xếp hạng và các tính năng Search. |
Allow + chặn khu vực nhạy cảm (wp-admin, login, tham số rác). Rate-limit nếu server yếu nhưng không “cấm cửa” toàn site. | Với Googlebot/bingbot: kiểm tra Reverse DNS + Forward DNS từ IP log để xác thực bot thật. |
| SEO Tools (crawl phân tích/so sánh) |
AhrefsBot SemrushBot (các biến thể hay gặp: SemrushBot, SemrushBot-SA, SemrushBot-SI, SemrushBot-BA, SemrushBot-OCOB, SemrushBot-SWA…) MJ12bot (Majestic) DotBot (Moz) | Thu thập dữ liệu link/onpage/technical để hiển thị trong công cụ SEO (backlink, audit, template…). |
Rate-limit (giờ hành chính/ban đêm tuỳ tải). Allow có kiểm soát nếu cần cho đối tác/đội SEO; Block nếu crawl quá đà làm nghẽn server. | Ưu tiên nhận diện theo User-Agent và (nếu có) đối chiếu bot “verified” trong hệ WAF/CDN hoặc log pattern ổn định. |
| AI Training Crawlers (thu thập dữ liệu huấn luyện) |
GPTBot (OpenAI) ClaudeBot (Anthropic) CCBot (Common Crawl) | Thu thập nội dung công khai để đưa vào tập dữ liệu huấn luyện / kho dữ liệu nền. |
Allow chọn lọc: cho “knowledge pages” (wiki/KB) ăn, hạn chế “money/sensitive pages”. Nếu không muốn bị thu thập: Disallow theo UA trong robots.txt, và chặn thêm ở WAF nếu cần. | Kiểm tra UA + đối chiếu chính sách bot theo tài liệu chính thức; với CCBot có khuyến nghị kiểm tra IP/rDNS do có tình trạng giả mạo. |
| AI Search / Index Bots (để xuất hiện link trong AI Search) |
OAI-SearchBot (OpenAI) Claude-SearchBot (Anthropic) PerplexityBot | Crawl/index để hiển thị website như nguồn tham khảo trong kết quả tìm kiếm của nền tảng AI. |
Allow (nếu mục tiêu là “được dẫn link”). Nếu dùng WAF: whitelist theo UA + IP range chính thức (đừng chỉ match mỗi UA). | Kết hợp User-Agent + IP ranges chính thức (khi nền tảng công bố) để tránh bot giả. |
| User-triggered Fetchers (fetch theo yêu cầu người dùng) | OpenAI: ChatGPT-User Khác: có thể có fetcher riêng tuỳ nền tảng (hãy xác nhận bằng log hoặc Verified Bots) | Khi người dùng hỏi, hệ thống AI sẽ “fetch” trang để đọc/trích dẫn tại thời điểm đó. |
Allow nếu muốn được trích dẫn theo phiên hỏi đáp. Rate-limit mềm (đừng bóp như bot rác), và đảm bảo trả HTML sạch (canonical chuẩn, nội dung không phụ thuộc JS nặng). | Kết hợp User-Agent + hành vi (rate/path/status) + (nếu có) Verified Bots để tránh bot giả. |
| Page Preview (bot tạo preview khi share link) | FacebookExternalHit (facebookexternalhit) | Lấy title/description/thumbnail để hiển thị khi chia sẻ link lên mạng xã hội. |
Allow (để share link đẹp). Chặn/throttle chỉ khi bị lợi dụng để scrape ảnh/meta hàng loạt. | Nhận diện UA + tần suất request theo sự kiện share (thường theo “đợt”, không crawl liên tục như bot rác). |
| Robots.txt control token (token điều khiển, không nhất thiết thấy trong log) | Google-Extended (robots.txt token) | Điều khiển việc nội dung bị dùng cho một số mục đích AI/grounding của Google; không phải lúc nào cũng có UA HTTP riêng. | Dùng khi muốn “tách” chính sách: vẫn cho Googlebot crawl để SEO, nhưng kiểm soát phần dùng cho AI theo Google-Extended. | Lưu ý: token này có thể không xuất hiện như UA riêng trong log, vì crawling có thể dùng UA Google hiện có. |
| Bad Bots / Scanner / Scraper (bot phá/giả danh) | Thường UA rỗng, UA giả browser, hoặc UA “lạ” không ổn định | Scan lỗ hổng (wp-admin, xmlrpc, plugin path), crawl URL rác/param, scrape bảng/FAQ, bắn request dày để làm nghẽn. |
Block ở WAF + rule theo path/ASN/geo/rate-limit. Chặn trước khi vào WordPress để giảm CPU/PHP. | Dấu hiệu thường gặp: 404 spike, request vào đường dẫn nhạy cảm, tốc độ bất thường, pattern không giống bot verified. |
UA (User-Agent) là chuỗi nhận diện client/bot gửi trong HTTP header. WAF (Web Application Firewall) là lớp tường lửa ứng dụng web, chặn request xấu trước khi chạm vào WordPress/PHP.
Verified bot là bot đã được một nền tảng (thường là CDN/WAF) xác minh danh tính bằng IP validation hoặc cơ chế xác thực riêng.
Ví dụ: trong Cloudflare có danh mục “Verified Bots” và có thể lọc theo category để set rule.
5.6. Danh sách bot “nên allow” tối thiểu (nuôi bot để crawl ít mà trúng) #
Bot tìm kiếm hợp lệ nên được allow để crawl/index ổn định, vì đây là “đầu vào” tạo traffic bền vững và cơ hội được AI trích dẫn. Allow không có nghĩa là thả cửa. Hãy dọn crawl trap và tối ưu đường đi (sitemap, internal link, canonical) để bot tự crawl “đúng phần”.
- Googlebot (bao gồm biến thể Image/Video/News nếu xuất hiện trong log)
- Bingbot
5.7. Danh sách bot “nên rate-limit” (hữu ích nhưng dễ tốn tài nguyên) #
Nhóm SEO tools tạo giá trị cho team, nhưng nếu để crawl tự do sẽ ăn crawl budget và tải server. Rate-limit theo phút/giờ + ưu tiên cache sẽ giữ lợi ích phân tích mà không làm web ì.
- AhrefsBot (crawler phục vụ bộ dữ liệu link)
- SemrushBot (crawler phục vụ audit/onpage & research)
- MJ12bot (crawler phục vụ dữ liệu link Majestic)
5.8. SOP phân loại bot từ log (5 phút là ra quyết định) #
SOP này giúp biến “một User-Agent lạ” thành quyết định rõ ràng: allow, rate-limit hay block. Không tin User-Agent một mình. Luôn nhìn thêm IP, hành vi và đường dẫn bị hit.
Output: 1 dòng nhãn cho bot (Category + Action) + 1 rule triển khai (WAF/server/robots) + 1 ghi chú kiểm tra an toàn SEO sau khi áp dụng.
- ☐ Lấy 20–50 dòng log của bot đó: IP, UA, path, status code, request/phút.
- ☐ Nhìn “mục tiêu” qua path: có hit
/wp-login.php,/xmlrpc.php,/?s=, tham số lọc/排序… không? - ☐ Nhìn “hành vi”: burst theo giây/phút hay crawl đều? tỷ lệ 404/403/429 có cao bất thường?
- ☐ Nếu tự xưng Google/Bing: verify bằng DNS/IP (đừng allowlist chỉ vì UA giống).
- ☐ Map vào 6 nhóm ở bảng 5.5 → chọn action: Allow / Rate-limit / Block.
- ☐ Triển khai ở lớp gần cửa nhất: WAF/CDN trước → server → WordPress.
- ☐ Chạy “Checklist kiểm tra an toàn SEO” (robots 200, sitemap ok, 5xx không tăng, Googlebot vẫn crawl trang quan trọng).
6. Tối ưu để AI trích dẫn: cấu trúc Answer-first + entity + bằng chứng #
AI thường trích nội dung có câu trả lời ngắn ngay dưới tiêu đề, thuật ngữ nhất quán, tiêu chí đúng/sai, bảng so sánh và checklist có output. Muốn AI trích đúng thì phải “dạy cách đọc”: nội dung rõ, có cấu trúc, có bằng chứng và có schema hỗ trợ.
| Yếu tố | AI dễ trích khi | AI khó trích khi | Cách làm nhanh |
|---|---|---|---|
| Answer-first | 2 dòng đầu trả lời thẳng | Vòng vo | Mỗi H2/H3 có 2 dòng kết luận |
| Entity nhất quán | Gọi 1 tên xuyên bài | Đổi thuật ngữ | Tạo bộ thuật ngữ (DefinedTermSet) |
| Bằng chứng | Có “Đúng khi / Sai khi” | Chỉ lời khuyên chung | Chuyển lời khuyên thành điều kiện |
| Cấu trúc | Bảng + checklist + ví dụ | Chỉ kể chuyện | Mỗi mục có ít nhất 1 bảng + 1 checklist |
Tham khảo nội bộ: AI Overview Friendly và SGE & AI Overview Tracking.
7. Dashboard theo dõi bot: từ log đến quyết định (chặn gì, sửa gì, ưu tiên gì) #
Dashboard bot phải trả lời 3 câu: bot nào ăn tài nguyên, URL nào bị đập nhiều nhất, và Googlebot có còn crawl đúng trang quan trọng không. Đo để ra backlog: chặn ở lớp nào, dọn crawl trap ở đâu, tối ưu trang nào để tăng AI cite.
| Khối | Chỉ số | Nguồn | Hành động khi tăng |
|---|---|---|---|
| Bot Load | Request/phút, băng thông | CDN/server log | WAF rate-limit, block pattern |
| Top URL bị hit | Top path | Log | Chặn endpoint, dọn param |
| Status Codes | 403/404/429/5xx | Log | Kiểm rule mới, rollback nếu cần |
| Googlebot Health | Hit sitemap/money page | Log + GSC | Kiểm internal link, canonical, robots |
Nền tảng nội bộ: Log File Analysis.
8. 3 tình huống thực tế (site Việt) và cách xử lý #
80% case bot traffic rơi vào: brute-force WP, crawl trap từ tham số lọc/sort, và scraper copy nội dung. Mỗi case cần đúng “thuốc”: brute-force chặn ở WAF, crawl trap xử lý IA/param, scraper chặn theo hành vi + bảo toàn canonical.
| Tình huống | Dấu hiệu | Nguyên nhân gốc | Xử lý ưu tiên |
|---|---|---|---|
| Web chậm ban đêm | Request tăng, GA4 user không tăng | Scanner/brute-force | WAF rate-limit + chặn endpoint nhạy cảm |
| Google crawl lung tung | Bot hit URL rác nhiều | Crawl trap | Dọn param + internal link + canonical |
| Bài bị scrape | Nhiều request theo pattern copy | Scraper farm | Challenge/bot rule + theo dõi referrer |
9. Lỗi thường gặp khi chặn bot và cách sửa (thực chiến) #
Lỗi nguy hiểm nhất là chặn nhầm Googlebot hoặc chặn nhầm đường dẫn hợp lệ; lỗi phổ biến nhất là dùng robots.txt như “công tắc ẩn index”. Mọi rule cần có log trước/sau và checklist kiểm tra để tránh “tối ưu mù”.
| Lỗi | Hậu quả | Dấu hiệu | Cách sửa |
|---|---|---|---|
| Block nhầm Googlebot | Index/refresh chậm | Trang mới vào index chậm | Gỡ rule, verify bot trước khi block |
| Robots chặn quá rộng | Mất crawl URL hợp lệ | URL quan trọng không được crawl | Chặn theo pattern cụ thể, kiểm bằng log |
| Không cho robots.txt truy cập | Bot không đọc luật | Crawl lỗi bất thường | Đảm bảo robots.txt trả 200, nhanh |
10. Checklist triển khai 90 phút + checklist kiểm tra an toàn SEO #
90 phút đủ để giảm phần lớn bot rác nếu làm theo thứ tự: đo log → phân loại → chặn WAF → chặn server → chỉnh robots → kiểm tra lại. Làm nhanh nhưng phải có tiêu chí đúng/sai và số trước-sau để chứng minh hiệu quả.
| Bước | Output | Thời gian | Tiêu chí đạt |
|---|---|---|---|
| Xuất log 24h | Top UA/URL/IP | 10’ | Có danh sách Top 20 |
| Phân loại bot | Allow/Rate-limit/Block | 10’ | Không chặn nhầm bot tốt |
| WAF rule | Rate-limit + block endpoint | 15’ | Giảm hit vào login/xmlrpc |
| Server rule | Chặn path/rate | 15’ | Giảm 403/404 do bot xấu |
| robots.txt | Chặn đường cụt + sitemap | 15’ | Không chặn nhầm URL quan trọng |
| Kiểm tra lại | Bảng “an toàn SEO” | 25’ | Googlebot vẫn crawl ổn |
- ☐ (10’) Xuất log 24h: Top UA/URL/IP lỗi
- ☐ (10’) Gắn nhãn: Allow / Rate-limit / Block
- ☐ (15’) WAF: rate-limit wp-login, block xmlrpc (nếu không dùng)
- ☐ (15’) Server: chặn endpoint nhạy cảm, rate-limit nếu burst
- ☐ (15’) robots.txt: chặn search/param theo pattern rõ, khai sitemap
- ☐ (10’) Verify Googlebot nếu có nghi ngờ bị chặn nhầm
- ☐ (15’) Ghi số trước-sau: request/phút, 5xx, top URL bị đập
Checklist kiểm tra an toàn SEO:
- ☐ robots.txt trả về 200 và tải nhanh (không 403/5xx, không redirect vòng).
- ☐ Sitemap index truy cập được và cập nhật đúng (không 404, không trả 5xx).
- ☐ Không tăng 5xx sau khi triển khai rule (so sánh 24h trước và 24h sau).
- ☐ Googlebot vẫn crawl đều sitemap và các trang quan trọng (money page, pillar, bài mới).
- ☐ Không chặn nhầm CSS/JS cần render (đặc biệt với theme/plugin cần asset riêng).
- ☐ Không chặn nhầm endpoint phục vụ người dùng thật (checkout, form submit, payment, API hợp lệ).
- ☐ 403/429 tăng chỉ tập trung ở endpoint nhạy cảm (wp-login/xmlrpc), không lan sang nội dung.
- ☐ Coverage/Indexing trong GSC không xuất hiện spike lỗi bất thường sau thay đổi (Excluded tăng đột biến cần soi).
- ☐ Crawl Stats (GSC) không tụt mạnh do tự chặn nhầm (requests/day, downloaded KB, avg response time).
- ☐ Log cho thấy bot xấu giảm hit vào URL rác, còn bot tốt tăng tỷ lệ hit vào URL có giá trị.
11. Hiểu lầm và tranh luận phổ biến (để khỏi làm sai) #
3 hiểu lầm phổ biến: robots.txt là cách “ẩn index”, chặn theo User-Agent là đủ, và chặn càng nhiều bot càng tốt. Vận hành đúng phải dựa vào log + hành vi. “Chặn đúng” quan trọng hơn “chặn nhiều”.
| Hiểu lầm | Vì sao sai | Cách đúng | Ngoại lệ |
|---|---|---|---|
| Robots.txt = ẩn khỏi Google | Robots.txt chủ yếu điều phối crawl; URL vẫn có thể xuất hiện nếu có link trỏ tới. | Nội dung không muốn xuất hiện: dùng noindex hoặc chặn truy cập bằng auth. | Site nội bộ không public, không có backlink và không mở internet. |
| Chặn theo User-Agent là đủ | User-Agent bị giả rất dễ. | Chặn theo hành vi (rate), theo path nhạy cảm và theo tín hiệu lỗi; verify bot quan trọng bằng DNS khi cần. | Scanner phổ biến có UA cố định, có thể block UA như một lớp phụ. |
| Chặn càng nhiều bot càng tốt | Chặn nhầm bot tốt làm hại crawl/index; mất cơ hội cập nhật nội dung mới. | Allow bot tìm kiếm, tối ưu đường crawl; chỉ chặn bot xấu và crawl trap. | Website yêu cầu khóa dữ liệu theo policy (ví dụ nội dung trả phí). |
12. Kết quả mong muốn và kinh nghiệm vận hành #
Kết quả tốt là bot xấu giảm mạnh, server ổn định hơn, Googlebot crawl tập trung vào trang quan trọng, và nội dung có cấu trúc để tăng khả năng AI trích dẫn. Đừng chỉ đo “đã chặn bao nhiêu”; hãy đo “có giữ được đường crawl đúng và dữ liệu sạch không”.
| Chỉ số | Trước | Sau (kỳ vọng) | Cách đo |
|---|---|---|---|
| Request/phút | Spike bất thường | Ổn định hơn (spike giảm rõ) | CDN/server analytics |
| 5xx | Tăng khi bot burst | Giảm | Log status code |
| Top URL bị đập | wp-login/xmlrpc/search/param | Giảm hit | Top path 24h |
| Googlebot hit money page | Không đều | Đều hơn | Log + GSC Crawl Stats |
Kinh nghiệm vận hành: Chặn bot “đúng” luôn đi kèm 2 việc: (1) dọn URL rác/crawl trap để Googlebot không lạc, (2) chuẩn hóa content theo Answer-first để bot tốt đọc nhanh và AI trích đúng. Chỉ chặn mà không dọn đường đi thì bot vẫn tốn quota vào phần vô nghĩa.
13. Nguồn tham khảo chính thức của Google #
Các trang dưới đây là nguồn chuẩn để đối chiếu khi audit robots, crawl và verify bot. Ưu tiên Google Search Central/Crawling Infrastructure để tránh “mẹo truyền miệng”.
- Robots.txt: giới thiệu và cách Google dùng
- Robots.txt spec Google hỗ trợ
- Googlebot và cách verify
- Verify Google crawler requests
- Optimize crawl budget
- Danh sách Google crawlers (có Google-Extended)
14. FAQ về Bot Traffic (hỏi nhanh đáp gọn) #
Phần này gom các câu hỏi thực chiến khi chặn bot, nuôi bot và tối ưu để AI trích dẫn. Mỗi câu trả lời đi thẳng vào cách làm và tiêu chí đúng/sai để dễ áp dụng.
Bot Traffic là gì? #
Bot Traffic là tổng lượng request do bot (crawler, scraper, scanner) tạo ra thay vì người dùng thật, trong bối cảnh vận hành website và Technical SEO.
Ví dụ: GA4 không tăng user nhưng server load tăng vì bot quét /wp-login.php hoặc URL tham số lọc.
Vì sao Bot Traffic làm web chậm nhưng GA4 không tăng? #
Nguyên nhân chính: bot tạo nhiều request ngắn, burst theo phút/giây và đánh vào endpoint nặng (login, search, API), khiến PHP/MySQL bận nhưng không tạo phiên người dùng hợp lệ trong GA4.
Đúng khi: log tăng request/phút, 403/429 tăng, nhưng GA4 users/sessions đứng yên.
Có nên chặn bot bằng robots.txt không? #
Robots.txt phù hợp để điều phối crawl với bot tuân chuẩn (chặn đường cụt, khai sitemap), không phải lớp chặn bảo mật.
Sai khi: dùng robots.txt như cách “ẩn khỏi Google” hoặc chặn quá rộng làm mất crawl URL hợp lệ.
User-Agent có đủ để nhận diện bot không? #
Không đủ. User-Agent là “nhãn” và bị giả rất dễ; cần nhìn thêm IP, rate truy cập, path, tỷ lệ lỗi (403/404/429) và pattern quét.
Đúng khi: quyết định chặn dựa trên hành vi + bằng chứng log, không dựa UA một mình.
Làm sao phân biệt Googlebot thật với bot giả? #
Cách chắc nhất: xác minh bằng reverse DNS và forward DNS với IP tự xưng Googlebot hit nhiều trong log.
Sai khi: thấy UA “Googlebot” là tin ngay rồi allowlist toàn bộ.
Nên chặn bot ở lớp nào để hiệu quả nhất? #
Ưu tiên: chặn càng gần “cửa” càng tốt: WAF/CDN → server (Nginx/Apache) → WordPress. Robots.txt chỉ là lớp hướng dẫn.
Đúng khi: bot xấu bị chặn trước khi vào PHP/MySQL, giảm tải rõ rệt.
Website không có Nginx/Apache thì làm sao chặn bot? #
Cách làm thực tế: dùng WAF/CDN (ví dụ Cloudflare) để rate-limit/challenge theo path và hành vi; kết hợp WordPress hardening (2FA, limit login, tắt xmlrpc nếu không dùng).
Đúng khi: request vào /wp-login.php và /xmlrpc.php giảm mạnh dù không chạm server config.
“Nuôi bot” nghĩa là gì và làm sao để bot tốt crawl đúng? #
“Nuôi bot” là tối ưu để bot tốt crawl ít mà trúng: sitemap chuẩn, internal link theo cụm, canonical sạch, giảm redirect vòng, dọn crawl trap do tham số.
Đúng khi: log cho thấy Googlebot hit đều sitemap và money page, thay vì sa vào URL rác.
Chặn tham số /*?* trong robots.txt có an toàn không? #
Thường không an toàn nếu site có trang hợp lệ dùng query (tracking, filter hợp pháp, tìm kiếm nội bộ cần dùng). Nên chặn theo pattern cụ thể dựa trên log.
Đúng khi: chỉ chặn các tham số tạo crawl waste như replytocom, orderby, filter rác… sau khi đã thấy chúng bị bot crawl nhiều.
Tối ưu gì để nội dung dễ được AI trích dẫn? #
Ưu tiên 4 thứ: 2 dòng trả lời ngay dưới mỗi H2/H3, thuật ngữ nhất quán (entity), tiêu chí “Đúng khi/Sai khi”, và bảng + checklist có output.
Đúng khi: nội dung có cấu trúc rõ, schema khớp nội dung thật và trang quan trọng được crawl/index ổn định.
Checklist kiểm tra an toàn SEO sau khi chặn bot gồm gì? #
Kiểm tra tối thiểu: robots.txt 200, sitemap truy cập được, 5xx không tăng, Googlebot vẫn crawl sitemap/money page, không chặn nhầm asset/endpoint người dùng thật.
Đúng khi: bot xấu giảm, nhưng crawl của bot tìm kiếm vẫn “khỏe” và không xuất hiện spike lỗi trong GSC.
15. Lời kết #
Bot Traffic không phải kẻ thù, nó là hệ sinh thái. Chặn bot xấu, dẫn bot tốt, và trình bày nội dung rõ để AI trích dẫn đúng. Khi có log + checklist + số trước-sau, quyết định kỹ thuật không còn dựa trên cảm giác mà dựa trên bằng chứng.




Bước tiếp theo
Muốn SEO lên top bền vững, hãy đi tiếp theo đúng cấp độ của bạn
Bài viết này chỉ là một phần trong hệ thống SEO của VLINK Asia. Bạn có thể đọc thêm tài liệu miễn phí, bắt đầu từ nền tảng, học full-stack SEO hoặc làm trực tiếp trên website thật của mình.
Trung tâm tài liệu
Kho tài liệu SEO thực chiến về Entity SEO, SEO cho AI, technical SEO, content, internal link, KPI, schema và cấu trúc website.
Vào Trung tâm tài liệuSEO Launchpad
Khóa học SEO nền tảng 8 buổi trong 1 tháng, phù hợp với người mới hoặc team cần hiểu đúng SEO trước khi triển khai sâu.
Xem SEO LaunchpadKhóa học SEO Master
Chương trình 36 buổi trong 3 tháng, học SEO tổng thể từ chiến lược, technical, content, entity, schema, internal link đến đo lường.
Xem SEO MasterMentor SEO 1:1
Mentor trực tiếp trên website của bạn: rà URL, menu, cấu trúc nội dung, internal link, KPI, landing page và kế hoạch SEO thực tế.
Xem Mentor SEO 1:1